
Panda photo: flickr.com / Gabriele Gherardi

We’ve touched previously on the concept of adversarial examples—the class of tiny changes that, when fed into a deep-learning model, cause it to misbehave. In March, we covered UC Berkeley professor Dawn Song’s talk at our annual EmTech Digital conference about how she used stickers to trick a self-driving car into thinking a stop sign was a 45-mile-per-hour sign, and how she used tailored messages to make a text-based model spit out sensitive information like credit card numbers. In April, we similarly talked about how white hat hackers used stickers to confuse Tesla Autopilot into steering a car into oncoming traffic.
In recent years, as deep-learning systems have grown more and more pervasive in our lives, researchers have demonstrated how adversarial examples can affect everything from simple image classifiers to cancer diagnosis systems, leading to consequences that range from the benign to the life-threatening. Despite their danger, however, adversarial examples are poorly understood. And researchers have worried over how—or even whether—the problem can be solved.
A new paper from MIT now points toward a possible path to overcoming this challenge. It could allow us to create far more robust deep-learning models that would be much harder to manipulate in malicious ways. To understand its significance, let’s first review the basics of adversarial examples.
As we’ve noted many times before, deep learning’s power comes from its excellent ability to recognize patterns in data. Feed a neural network tens of thousands of labeled animal photos, and it will learn which patterns are associated with a panda, and which patterns are associated with a monkey. It can then use those patterns to identify new images of animals that it has never seen before.
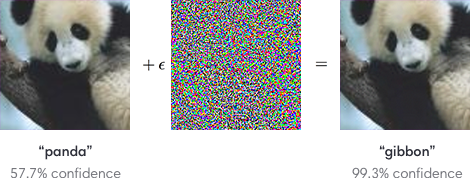
But deep-learning models are also brittle. Because an image recognition system relies only on pixel patterns rather than a deeper conceptual understanding of what it sees, it’s easy to trick the system into seeing something else entirely—just by disturbing the patterns in the right way. Here’s a classic example: add a little noise to an image of a panda, and a system will classify it as a gibbon with nearly 100% confidence. The noise, here, is the adversarial attack.
For a few years now, researchers have observed this phenomenon, particularly in computer vision systems, without really knowing how to get rid of such vulnerabilities. In fact, a paper presented last week at the major AI research conference ICLR questioned whether adversarial attacks are inevitable . It would seem that no matter how many panda images you feed an image classifier, there will always be some kind of perturbation that you can design to throw the system off.
But the new MIT paper demonstrates that we’ve been thinking about adversarial attacks wrong. Rather than think of ways to amass more and better training data to feed to our system, we should fundamentally rethink the way we approach training it.
It showed this by identifying a rather interesting property of adversarial examples that helps us grasp why they’re so effective. The seemingly random noise or stickers that trigger misclassifications are actually exploiting very precise, minuscule patterns that the image system has learned to strongly associate with specific objects. In other words, the machine isn’t misbehaving when it sees a gibbon where we see a panda. It is indeed seeing a pattern of pixels, imperceptible to humans, that occurred far more often in the gibbon photos than panda photos during training.
The researchers illustrated this by running an experiment: they created a data set of dog images that had all been changed in tiny ways that would cause a standard image classifier to misidentify them as cats. They then mislabeled the images as cats and used them to train a new neural network from scratch. After training, they showed the neural network actual cat images, and it correctly identified all of them as cats.
What that suggested to the researchers is that in every data set, there are two types of correlations: patterns that actually correlate with the meaning of the data, such as the whiskers in a cat image or the fur colorations in a panda image, and patterns that happen to exist within the training data but do not generalize to other contexts. These latter “misleading” correlations, as we’ll call them, are the ones exploited in adversarial attacks. In the diagram above, for example, the attack takes advantage of a pixel pattern falsely correlated with gibbons by burying those imperceptible pixels within the panda image. The recognition system, trained to recognize the misleading pattern, then picks up on it and assumes it’s looking at a gibbon.
This tells us that if we want to eliminate the risk of adversarial attacks, we need to change the way we train our models. Currently, we let the neural network pick whichever correlations it wants to use to identify objects in an image. But as a result, we have no control over the correlations it finds and whether they’re real or misleading. If, instead, we trained our models to remember only the real patterns—those actually tied to the pixels’ meaning—it would theoretically be possible to produce deep-learning systems that can’t be perverted in this way for harm.
When the researchers tested this idea by using only real correlations to train their model, it did in fact mitigate the model’s vulnerability: it was successfully manipulated only 50% of the time, whereas a model trained on both real and false correlations could be manipulated 95% of the time.
Put another way, it seems that adversarial examples are not inevitable. But we need more research to eliminate them entirely.
This story originally appeared in our Webby-nominated AI newsletter The Algorithm. To have more stories like this delivered directly to your inbox, sign up here. It's free.
