
Jack Taylor / Stringer / Getty

Machine speech is something of a disappointment. Even the best text-to-speech systems have a mechanical quality and lack the basic changes in intonation that humans use. Stephen Hawking’s much copied speech system is a case in point.
That’s something of a surprise given the huge advances in machine learning in recent years. Surely the techniques that have worked so well in recognizing faces and objects and then producing realistic images of them should work equally well with audio. Not really.
At least, not until today. Enter Sean Vasquez and Mike Lewis at Facebook AI Research, who have found a way to overcome the limitations of text-to speech systems to produce remarkably lifelike audio clips generated entirely by machine. Their machine, called MelNet, not only reproduces human intonation but can do it in the same voice as real people. So the team trained it to speak like Bill Gates, among others. The work opens the possibility of more realistic interaction between humans and computers, but it also raises the specter of a new era of fake audio content.
First some background. The slow progress on realistic text-to-speech systems is not from lack of trying. Numerous teams have attempted to train deep-learning algorithms to reproduce real speech patterns using large databases of audio.
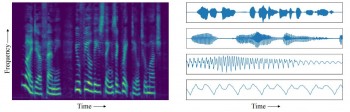
The problem with this approach, say Vasquez and Lewis, is with the type of data. Until now, most work has focused on audio waveform recordings. These show how the amplitude of sound changes over time, with each second of recorded audio consisting of tens of thousands of time steps.
These waveforms show specific patterns at a number of different scales. During a few seconds of speech, for example, the waveform reflects the characteristic patterns associated with sequences of words. But at the scale of microseconds, the waveform shows characteristics associated with the pitch and timbre of the voice. And at other scales, the waveform reflects the speaker’s intonation, the phoneme structure, and so on.
Another way of thinking about these patterns is as correlations between the waveform at one time step and at the next time step. So for a given time scale, the sound at the beginning of a word is correlated with the sounds that follow.
Deep-learning systems ought to be good at learning these types of correlations and reproducing them. The problem is that the correlations act over many different time scales, and deep-learning systems can study correlations over only limited time scales. That’s because of a type of learning process they employ, called backpropagation, which repeatedly rewires the network to improve its performance on the basis of the examples it sees.
The repetition rate limits the time scale over which correlations can be learned. So a deep-learning network can learn correlations in audio waveforms over long time scales or short ones, but not both. That’s why they perform so badly at reproducing speech.
Vasquez and Lewis have a different approach. Instead of audio waveforms, they use spectrograms to train their deep-learning network. Spectrograms record the entire spectrum of audio frequencies and how they change over time. So while waveforms capture the change over time of one parameter, amplitude, spectrograms capture the change over a huge range of different frequencies.
This means the audio information is packed more densely into this type of data representation. “The temporal axis of a spectrogram is orders of magnitude more compact than that of a waveform, meaning dependencies that span tens of thousands of timesteps in waveforms only span hundreds of timesteps in spectrograms,” say Vasquez and Lewis.
That makes the correlations more accessible to a deep-learning system. “This enables our spectrogram models to generate unconditional speech and music samples with consistency over multiple seconds,” they say.
And the results are impressive. Having trained the system using ordinary speech from TED talks, MelNet is then able to reproduce the TED speaker’s voice saying more or less anything over a few seconds. The Facebook researchers demonstrate its flexibility using Bill Gates’s TED talk to train MelNet and then use his voice to say a range of random phrases.
This is the system saying “We frown when events take a bad turn” and “Port is a strong wine with a smoky taste.” Other examples are here.
“We frown when events take a bad turn”
“port is a strong wine with a smoky taste”
There are some limitations, of course. Ordinary speech contains correlations over even longer time scales. For example, humans use changes in intonation to indicate changes in topic or mood as stories evolve over tens of seconds or minutes. Facebook’s machine does not yet seem capable of that.
So while MelNet can create remarkably lifelike phrases, the team has not yet perfected longer sentences, paragraphs, or entire stories. That does not seem like a goal that is likely to be reached soon.
Nevertheless, the work could have a significant impact on human-computer interaction. Many conversations involve only short phrases. Telephone operators and help desks in particular can get by with a range of relatively short phrases. So this technology could automate these interactions in a way that is much more human-like than current systems.
For the moment, though, Vasquez and Lewis are tight-lipped about potential applications.
And as ever, there are potential problems with natural-sounding machines, particularly those that can mimic humans reliably. It doesn’t take much imagination to dream up scenarios in which this technology could be used for mischief. And for that reason, it is yet another AI-related advance that raises more ethical questions than it answers.
Ref: arxiv.org/abs/1906.01083 : MelNet: A Generative Model for Audio in the Frequency Domain