Search Me
Inside the launch of Stephen Wolfram’s new “computational knowledge engine.”


On the evening of April 27 a ferocious rain raked the windows beside Jamie Williams’s cubicle as the physicist sat, exhausted, immersed in the minutiae of food science. On the computer screen before him were raw tables of information from the U.S. Department of Agriculture, containing data on 7,000 foods, from blackberries to beef. He and a four-person team were “curating” the data, readying it for a new kind of online search. He combed through the tabs that identified 150 properties (nutrients, calories, carbohydrates, and so on), making sure the various abbreviations were consistent and readable by computers. He organized foods into groupings to facilitate natural-language queries. A search for nutritional information on “milk” would provide an average value, for example, while “skim milk” would provide a specific answer.
Williams wasn’t toiling in a redoubt of Silicon Valley Web entrepreneurs but in a midwestern citadel of science geeks: Wolfram Research, in Champaign, IL, housed in an office block overlooking a Walgreens and a McDonald’s. This was the corporate lair of Stephen Wolfram, the physicist and maker of Mathematica, which is generally acknowledged to be the most complete technical and graphical software for mathematicians, scientists, and engineers. Williams was working on something his company was calling a “computational knowledge engine”: Wolfram Alpha. In response to questions, Alpha was meant to compute answers rather than list Web pages. It would consist of three elements, honed by hand in Champaign: a constantly expanding collection of data sets, an elaborate calculator, and a natural-language interface for queries.
What might Wolfram’s system do that Google can’t? Say you wanted to know how much cholesterol and saturated fat lurked in a slab of your grandmother’s cornbread. You’d transcribe its ingredients from her yellowed index card to an online query bar, and Alpha would run computations and produce a USDA-style nutrition label. “Sure, you could go to Google, find out calories in a standard egg, and so on–but what a pain in the ass it would be!” exclaimed Wolfram Research cofounder Theodore Gray. “You’d need the data. And you’d need the data to be in forms that can be readily converted, if need be. And you’d need to add them up. You can do it, just as in earlier decades–you could go to the library to find a reference, and today you can go to Google or another search engine to get started. But we make it far easier.” With a conventional search engine, he added, “enter ‘one cup of sugar, one pound of flour,’ and it completely throws up all over your screen.”
This is one example of the sort of thing Alpha was meant to do: provide deeper, more specific, and more graphically dressed-up answers to certain kinds of questions–though a limited set at first. Queries for “D# major” would produce graphics of the musical scale, queries for “Venus” would produce detailed, current maps of the night sky; queries on pairs of companies would produce comparative charts and graphs. It would add extra information: a search for “New York London distance” would produce the answer in miles, kilometers, and nautical miles; a map showing the flight path; and a comparison of how long it would take a jet, a sound wave, and a light beam to make the trip. Ask it about a word (prefaced by the word word), and it would generate etymology tables and synonym networks. To do these sorts of things, it would start with math and science data sets and formulas already held in Mathematica, and build from there. Some of the new information, such as government data on food, would just need minor reorganization. That’s what Williams was doing. Other kinds, such as real-time stock data, required licensing. Still others, such as data on aircraft, would be gathered from open Web sources such as Wikipedia and Freebase, and cleaned up–curated.
Wolfram himself was in Boston, preparing to give the first public demonstration the next afternoon. (He’d already done demos for Tim Berners-Lee, inventor of the World Wide Web, and several technology-industry captains, including Microsoft’s Bill Gates, Google’s Sergey Brin, and Amazon’s Jeff Bezos.) I sat in Gray’s office, which seemed more like a shrine to the periodic table of the elements than a workplace: samples of nickel, chromium, selenium, sulfur, and dozens more adorned glass shelves. (He proudly opened a lead box and retrieved a dull metallic slab, about the size of two packs of cards. It was 11 pounds of uranium–not enriched, thankfully, but still mildly radioactive.) “It’s a limited notion that the only thing you can do with search today is basically a textual search of existing printed material,” Gray said. “That represents a huge failure of imagination.”
Down the hall, Eric Weisstein, an astronomer and creator of MathWorld, the online reference now hosted by Wolfram, sat in an office amid spider-plant cuttings in wax-paper cups (they are especially efficient at purifying air, he explained), putting the finishing touches on a comprehensive unit converter to drive some of Alpha’s results. “If you search the Web, there are hundreds, if not thousands, of sites where people can convert feet to meters,” Weisstein said. “But they are not flexible enough, authoritative enough, and in most cases they don’t have enough coverage.” Such calculators can’t tell you how many grams are in a cup of milk or a cup of flour (the answer varies by substance). And forget about using them to convert a “pinch” (380 milligrams, in the case of salt) or a “drop” (if it’s corn oil, one “metric drop” is 56 milligrams), or a “hogshead” (quite a lot of wine: 248 kilograms), much less units of thermal conductivity, international men’s hat sizes, or any kind of bushel. “Bushel is an important one. A bushel of soybeans is not the same as a bushel of wheat, is not the same as a bushel of volume, ain’t the same as a bushel of mass,” Weisstein said. “We’ve gone and built the world’s best unit converter!”
Throughout the building, and in remote locations, about 150 Wolfram staffers labored in similar fashion–some in pretty far-out fields. I found Ed Pegg in his cubicle, immersed in the subject of tiling. At his fingertips was the definitive reference, the 700-page Tilings and Patterns by Grünbaum and Shephard, describing everything from obscure crystallographic patterns in materials to the herringbones and basket weaves of brick walkways. There were so many variations: Islamic tiling patterns (octagons, hexagons, and two types of stars); double spirals made of nine-sided nested wedges; 14 kinds of patterns based on various pentagons. Although the tiling corpus would not be loaded by launch time, Pegg was creating ways for patterns to be combined and calculated. With these and other tools, a textile designer might create an Escher-like pattern (using interconnecting flowers, say, instead of lizards); a chemist might explore how a collection of molecules could fit together; a homeowner might generate a pattern for a new bathroom floor.
But first, Alpha had to launch–and the launch date was just three weeks off. Much remained unclear. Would the natural-language interface work well enough? Would the two supercomputers (which had just arrived at the data center outside of town) bear up on launch day–or would the site crash, as Cuil, the putative Google killer of 2008, had done? And would people really care to learn how many milliseconds it takes a light beam to go from New York to London? In Champaign, the developers were just trying to stamp out glitches. “There is a bit of a daunting feeling of knowing this never ends,” Williams confided, “even though this is launching.”
Gray stopped by Williams’s cubicle. The two men huddled over the computer screen, silent for a moment.
“Why won’t it work with two cups of flour and two eggs?” Gray asked, finally.
“Well,” Williams replied, “there’s a bug.”

Slow Semantics
In 1993 a newly minted University of Maryland graduate, a brainy Russian with an interest in computers, interned at Wolfram Research. He did some hands-on work on Mathematica’s kernel, or the core of the software. Then he went off to get his master’s degree at Stanford–and to cofound Google. Today Google handles 64 percent of all searches made by Americans, but the erstwhile Wolfram intern, Sergey Brin, is not entirely happy. He dominates an industry, he’s worth $12 billion, and he hobnobs at the World Economic Forum’s annual meeting in Davos, Switzerland. Search technology, however, hasn’t kept pace with his personal rise. “[T]here are important areas in which I wish we had made more progress,” Brin wrote in Google’s 2008 annual report. “Perfect search requires human-level artificial intelligence, which many of us believe is still quite distant. However, I think it will soon be possible to have a search engine that ‘understands’ more of the queries and documents than we do today. Others claim to have accomplished this, and Google’s systems have more smarts behind the curtains than may be apparent from the outside, but the field as a whole is still shy of where I would have expected it to be.”
Among all the leaders in Web search over the years–from Excite (went bankrupt) to Alta Vista (absorbed by Yahoo in 2003) to today’s top five players (Google, Yahoo, Microsoft, Ask, and AOL)–the core approach has remained the same. They create massive indexes of the Web–that is, their software continually “crawls” the Web, collecting phrases, keywords, titles, and links on billions of pages in order to find the best matches to search queries. Google triumphed because its method of ranking pages, based partly on analyzing the linking structure between them, produced superior results. But while the Web has expanded 10,000-fold over the past decade, search engines haven’t made comparable progress in their ability to find specific answers and then put them together intelligently. The Semantic Web–the long-envisioned system in which information is tagged to allow such processing–is still a long way off.
Last year Yahoo launched something called SearchMonkey, which allows Web-page publishers to improve search returns by adding tags telling the search engine’s software, “This is an address,” “This is a phone number,” and so on. (So now, if you search on Yahoo for a restaurant, you may receive, beyond a link to the restaurant’s page, bullets listing the restaurant’s address, its phone number, and a compilation of reviews.) “What SearchMonkey is doing is taking the promise of the Semantic Web and putting it out in the open so publishers can participate,” says Prabhakar Raghavan, head of Yahoo Labs. Google recently began doing something similar, called “rich snippets.”
But such ideas have been slow to spread across the Web, even though the World Wide Web Consortium (W3C), the international standard-setting body led by Berners-Lee, has set out specifications to help implement them more broadly. And even if the W3C standards were broadly applied, they do not offer much guidance on computation, says Ivan Herman, who heads the W3C’s semantic efforts from Amsterdam: “How this data is combined with numerical calculation and math processes is not well defined, and that is certainly an area in which we have to work.”
So while today’s search engines are increasingly broad and useful–expanding into new categories (maps, photographs, videos, news), learning to answer simple questions (“What is the population of New York?”), and even doing basic conversions (“What is 10 pounds in kilograms?”)–they aren’t particularly deep or insightful. “While Google is great,” says Daniel Weld, a computer scientist at the University of Washington and a Semantic Web researcher, “personally I would rather have the ship’s computer on the Starship Enterprise, where you ask high-level questions and it gives the answer, and explains the answer, and then you can say, ‘Why did you think that was true?’ and it takes you back to the source.”
As Stephen Wolfram sees it, he’s providing the infrastructure for answering questions in truly intelligent ways–albeit on subjects biased initially toward geeky domains. “We don’t have the problem of dealing with the vicissitudes of the stuff that’s just sort of out there on the Web,” he says. “We’ve bitten the bullet and said, ‘Let’s curate all this data ourselves!’ It would be great if the Semantic Web had happened and we could just go and pick up data and it would all fit beautifully together. It hasn’t happened.”
The Demo
At 3 p.m. on April 28, launch was still two weeks out as the 49-year-old Wolfram–graying, balding, and full of nervous energy–took his place at a Harvard Law School lectern, clad as usual in an oxford shirt, khakis, and Nike sneakers, to deliver the first public (and webcast) demonstration of Wolfram Alpha. Speaking in his soft English accent, he ran through some of the engine’s bag of tricks, such as entering strings of Gs, Cs, As, and Ts to obtain detailed data about the genes in which a DNA sequence appeared.
Over the previous two decades, Wolfram had come to be known for both his brilliance and his self-aggrandizement. A London-born prodigy, he skipped an undergraduate degree to receive his PhD in physics from Caltech when he was 20, and won a MacArthur Foundation “genius” grant two years later. He held a series of prestigious posts at Caltech, the Institute for Advanced Study at Princeton, and the University of Illinois. But in the mid-1980s he left academia to found Wolfram Research, and in 1988 the company issued the first version of Mathematica. The software contains vast libraries of mathematical functions, tools for visualizing data in two and three dimensions, and deep databases on astronomical bodies, chemical compounds, subatomic particles, socioeconomic matters, financial instruments, human genes and proteins, and some simple biographical information, among other things. And it produces wonderful visualizations: geometric shapes, molecular diagrams, orbit plots.
Fourteen years after the first release of Mathematica–a period during which he published no research–Wolfram birthed a 1,200-page tome, A New Kind of Science, which he thereafter referred to as NKS. In it, he posited that many complex systems and problems–from plant and animal morphologies to quantum mechanics–could be reduced to simple rules. In the New York Times, George Johnson proclaimed, “No one has contributed more seminally to this new way of thinking about the world.” But Wolfram’s own characterization–that the book “has been seen as initiating a paradigm shift of historic importance in science”–met with more than a little eye rolling. “The adjective Wolframian has entered the lexicon, to mean taking something that everyone knows and presenting it as this astounding discovery about the nature of reality,” says Scott Aaronson, a computer scientist at MIT (whose blog, Shtetl Optimized, is published on technologyreview.com). Aaronson does not deny that Mathematica is “very cool software,” but he says that NKS, while it has value as popular science, “has essentially had zero impact on the areas of computer science and physics that I know about.”
To Wolfram, Alpha now joins NKS as one of the great scientific endeavors in human history. He distributed a two-page list placing it at the end of a continuum that begins with the invention of arithmetic and written language and goes on to mention the Library of Alexandria, Isaac Newton, and the creation of the Encyclopedia Britannica. He positions Mathematica just before the invention of the World Wide Web in 1989; NKS earns a spot between Wikipedia and Web 2.0. He describes the final entry, Wolfram Alpha, as “defining a new kind of knowledge-based computing.”
A real-world validation of Alpha’s potential importance came partway into Wolfram’s Harvard Law talk. At 3:17 p.m., Google’s official blog announced a new service allowing people to search and compare public data, starting with federal census and labor data. The service would return not Web pages but Google-produced charts and graphs. (A search for “Ohio unemployment rate,” for example, would produce a chart of the data, plus ways to compare that rate to those of other states.) The blog post called it a way to start tapping vast realms of “interesting public data” on “prices of cookies, CO2 emissions, asthma frequency, high school graduation rates, bakers’ salaries, number of wildfires, and the list goes on.” Google had been working on the service for two years, since acquiring Trendalyzer, on whose technology the graphics are based; the company says the announcement’s timing was a coincidence. But clearly, the industry giant was acknowledging the same sort of deficit in Web search that Wolfram’s people were attacking.
Two weeks later–on the eve of the Wolfram launch–Google threw an event dubbed “Searchology,” at which it announced another new data-crunching service, Google Squared. The technology, now available on its Google Labs site, combines information from different Web sources and packages it into nice tables. A search for “roller coasters,” for example, produces a table of American amusement-park rides from Excalibur to Montezooma’s Revenge. Columns provide thumbnail photos, descriptions, heights, and lengths. Users can click on the results to delete errors in the original table and refine the search. Marissa Mayer, a Google vice president, said during the event that Google Squared “pushes search in an entirely new direction.” She added, “It is a hard computer science problem–to take this unstructured information and present it in a structured way.”
Google also said it would provide better real-time data in search results. If you search for “earthquakes San Francisco,” Google, like Alpha, will now push out the latest relevant reports from the U.S. Geological Survey. (It is doing something similar with real-time data on airline flights and sports scores.) Peter Norvig, Google’s research director, told me that the technologies represent a foretaste of the company’s efforts in finding, combining, and presenting numerical data. “I would say in general, our approach would be more toward open systems rather than closed, curated ones,” Norvig said, “but I do appreciate the broad kind of user interface [Wolfram Alpha is] providing, and the data analysis tools. We would like to do more of that. Maybe having him out there will push us to release more, faster–I don’t know.” Scott Kim, executive vice president for technology at the search engine Ask, was more direct in suggesting that Wolfram would have an influence. “I think it opens people’s eyes–the general public’s eyes–to what you can get out of a computational engine, and how that can be integrated into a search engine,” he said of Alpha. “This is absolutely part of the future of search, and there is a long way to go.”
Launch
Ever the showman, Stephen Wolfram made sure the two supercomputers were dramatically lit with blue and green LED lights. In the new data center near Champaign, he’d set up a slightly elevated command post for himself. He’d arranged for the event to be webcast. And at 10:30 p.m. on May 15, as a tornado watch covered much of Illinois, he mouse-clicked a tab labeled “Activate,” and a wall-mounted screen showed computer clusters blinking to life. “Statistically speaking, there will be some issues, and it’s only a question of what issues they are,” he said that night. But despite voltage fluctuations and earlier overloads on the supercomputers, Wolfram avoided a crash of the sort that bedeviled Cuil.
His engine itself still faced a big performance problem, however. As complete and elegant as it was when it knew something, there was much it did not know (and it was hard to guess what it might know). Wolfram Alpha isn’t sure what to do with your input was a frequent response from the site. This was mainly because of the huge gaps in its curated data; Alpha is a library whose shelves are only partly filled. It is largely blind to history, politics, literature, sports, social sciences, and pop culture. The site was also bedeviled by an inflexible natural-language interface. For example, if you searched for “Isaac Newton birth,” you got Newton’s birth date (December 25, 1642; you also learned that the moon was in the waxing-crescent phase that day). But if you searched for “Isaac Newton born,” Alpha choked. Aaronson tested it with me and found it couldn’t answer “Who invented the Web?” and didn’t know state-level GDP figures, only national ones. But it could ace all sorts of math questions, including a request for the surface area of the earth. Aaronson asked it, “What is the GDP of Ireland divided by the cosine of 42?” and received a chart reflecting the relevant calculations for GDP figures from 1970 to 2007, presented on a logarithmic scale.
Finally, there was a documentation problem. Clicking links revealed a variety of sources: the CIA’s World Factbook, the website Today in Science History, the U.S. Geological Survey, Dow Jones, and the Catalogue of Life, an internationally maintained index of the world’s known species. But nothing specified which source had provided which fact. (Gray says the company is working on adding such labels to specific facts and to computed results.)
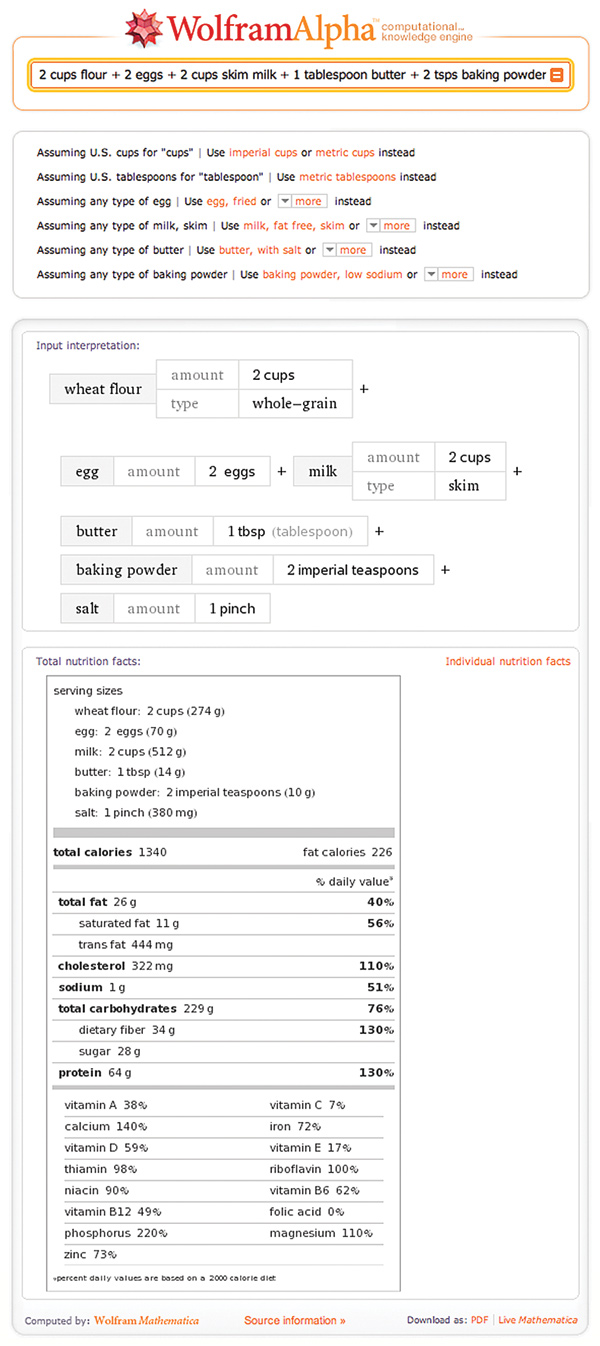
Cakewalk: On questions it can handle–especially computable ones in math, science, and engineering–Wolfram Alpha performs many original tricks. Presented with pancake ingredients (1), the engine offers possible variations (2), shows how it interpreted the input (3), and produces a combined nutrition label (4). Behind the scenes, Wolfram’s Mathematica software first performs any needed unit conversions (for example, converting “pinch of salt” to a computation-ready “380 milligrams of salt”). But an offer of “source information” (5) doesn’t trace facts to specific references.
But if you gave Wolfram Alpha every allowance–that is, if you asked it about subjects it knew, used search terms it understood, and didn’t care to know the primary source–it was detailed, intelligent, and graphically stunning. Searches for materials gave you diagrams of chemical compounds; searches on astronomy gave you maps of the night sky (geolocated on the basis of your computer’s IP address). It could do things the average person might want (such as generating customized nutrition labels) as well as things only geeks would care about (such as generating truth tables for Boolean algebraic equations). “Wolfram Alpha is an important advance in search technology in that it raises expectations about how content that is stored in databases should be searched,” Marti Hearst, a computer scientist at the University of California, Berkeley, and the author of Search User Interfaces, told me. But she added that it “has a long way to go before achieving its ambitious goals.”
Some of these problems will be addressed by adding more data, an effort Wolfram says will continue indefinitely. To help the process, the site includes links for people to submit individual facts, entire structured data sets, and even algorithms and models. Unlike Wikipedia–where the process of adding and editing information is free and open, with checks and balances provided by the community–Wolfram Alpha plans to maintain a more centralized form of control, saying that its “staff of expert curators” will check the data before adding anything to the corpus. But some believe that expansion will be difficult without some automated or community-driven process, and without indexing the Web as search engines do. “At a certain point, calculation isn’t so useful if there isn’t the raw data to drive it,” says Weld of the University of Washington. “Google Squared is more the trend that I think will win this race.”
Indeed, even granting that his engine is only a start, some skeptics doubt that Wolfram’s approach will work for more than niche applications. “Although I have graduated as a mathematician and have a huge respect for anything mathematical, I am not sure you can handle all of the miseries of this world by mathematical formula and computation,” says the W3C’s Ivan Herman. Norvig echoed this objection. “There are certain data sets for which that [approach] is appropriate. If you are talking about atomic weight of gold–if different labs are off on that, they are off to the fifth or sixth decimal place, who cares?” Norvig says. “But many other things, there is no consensus. It depends what the data is. It depends what type of calculation you want to do. And if it’s non-numeric data, then it’s less clear what sort of calculation you can do.” And Weld piled on: “Imagine a question like ‘Who are the most dangerous terrorists?’ That’s a real hard one. Is someone a terrorist? How do we assess danger? And danger to whom? It is computationally very difficult to do that kind of reasoning.”
Still, in some cases Wolfram’s obsession with computation could serve certain users better than do the market-share-obsessed major search companies, who are, quite naturally, most interested in helping the masses get better results on queries they are already performing. “Let’s say that reviews of a particular hotel are scattered around several sites,” says Yahoo’s Raghavan. “Giving a summary rating is much more in line with what users tend to ask, rather than saying they want the combined populations of the Balkan countries in Eastern Europe. There is always one guy out there who has an arcane question to ask, but we have to maniacally focus on satisfying 99 percent of the population really well.”
In its first two weeks, Wolfram Alpha processed 100 million queries and received 55,000 pieces of feedback, suggesting more than a niche level of interest in deeper answers. “What Wolfram Alpha will do,” Wolfram says, “is let people make use of the achievements of science and engineering on an everyday basis, much as the Web and search engines have let billions of people become reference librarians, so to speak.” A Firefox add-on has already surfaced, allowing searchers to display Alpha results alongside Google results. And Wolfram says the engine will undergo continual improvement. Three weeks after launch he announced the first broad update to its code and data, including enhancements to the natural-language interface, more data on subcountry regions (such as Wales), a new ability to search for a stock price on a specific date, and “more mountains added, especially in Australia.”
Wolfram says he has invested “tens of millions” of dollars in Wolfram Alpha, atop “hundreds of millions” spent developing Mathematica over two decades. Advertising has started appearing alongside results, and he plans to offer a professional subscription version with more features. A programming interface (called an API) allows developers to build applications that can make Wolfram Alpha searches. “We’ll see if this is an exercise in philanthropy or a thriving business,” he told me.
Even Aaronson allows that the real judges will be the people. “Millions of people will try it, and either it will be useful or it won’t–and that’s the real test,” he says. “It’s not some abstruse claim about the nature of reality. It’s here as a useful service, and the test is, do people find it useful or not?”
David Talbot is Technology Review’s chief correspondent.
