Intelligent Machines
Microsoft's Shiny New Toy
Photosynth is still a work in progress. It is dazzling, but what is it for?
At last March’s Technology, Entertainment, Design (TED) conference in Monterey, CA, a summit that’s been described as “Davos for the digerati,” the calm-voiced software architect from Microsoft began his demonstration abruptly, navigating rapidly across a sea of images displayed on a large screen. Using Seadragon, a technology that enables smooth, speedy exploration of large sets of text and image data, he dove effortlessly into a 300-megapixel map, zooming in to reveal a date stamp from the Library of Congress in one corner. Then he turned to an image that looked like a bar code but was actually the complete text of Charles Dickens’s Bleak House, zooming in until two crisp-edged typeset characters filled the screen, before breezily reverse-zooming back to the giant quilt of text and images.

Microsoft had acquired Seadragon the previous year–and with it the presenter, Blaise Agüera y Arcas. But Agüera y Arcas had not come to TED just to show off Seadragon. Soon he cut to a panorama tiled together from photos of the Canadian Rockies; the mosaic shifted as he panned across it, revealing a dramatic ridgeline. Next came an aerial view of what appeared to be a model of a familiar building: Notre Dame Cathedral. The model, Agüera y Arcas explained, had been assembled from hundreds of separate images gathered from Flickr. It was a “point cloud”–a set of points in three-dimensional space.
As he talked, Agüera y Arcas navigated teasingly around the periphery of Notre Dame, which repeatedly came alive and dimmed again. The effect of hurtling through shifting images and focal points was softened by subtle transitional effects. It felt like a deliberately slowed reel of frame-by-frame animation; the effect was jolting. The crowd watched in wonder as Agüera y Arcas pushed deeper into the front view of the building’s archway, ending with a tight close-up of a gargoyle. Some of the images the technology had drawn on were not even strictly photographic: it had searched Flickr for all relevant images, including a poster of the cathedral. What Agüera y Arcas was demonstrating wasn’t video, but neither was it merely a collection of photos, even a gargantuan one. It was also like a map, but an immersive one animated by the dream logic of blurring shapes and shifting perspectives.
This was Photosynth–a technology that analyzes related images and links them together to re-create physical environments in a dazzling virtual space. The technology creates a “metaverse,” Agüera y Arcas said (for more on the nascent blending of mapping technologies like Google Earth and the fantastic realms of games like Second Life, see “Second Earth,” July/August 2007); but it also constitutes the “long tail” of Virtual Earth, Microsoft’s competitor to Google Earth, because of its ability to draw from and contribute to the wealth of local mapping and image data available online. It could provide “immensely rich virtual models of every interesting part of the earth,” he said, “collected not just from overhead flights and from satellite images and so on, but from the collective memory.” At which point the presentation ended as abruptly as it had begun some six minutes earlier. Agüera y Arcas’s concluding statement met with a thunder of applause.
Beyond Image Stitching
Photosynth was born from what Agüera y Arcas calls the marriage of Seadragon and Photo Tourism, a Microsoft project intended to revolutionize the way photo sets are packaged and displayed. Photo Tourism had begun as the doctoral thesis of a zealous 26-year-old University of Washington graduate student named Noah Snavely. One of Snavely’s advisors was Rick Szeliski, a computer-vision researcher at Microsoft Research, the company’s R&D arm. “I described the need for the good elements of a strong slide show, like great composition,” recalls Szeliski, whose earlier work at Microsoft had helped develop the image-stitching technology now commonly used in digital cameras to fill a wider or taller frame. He also sought fluidity between images and a sense of interactivity in viewing them.
Working with Szeliski and a University of Washington professor named Steve Seitz, Snavely was intent on coding a way forward through a computationally forbidding challenge: how to get photos to merge, on the basis of their similarities, into a physical 3-D model that human eyes could recognize as part of an authentic, real-world landscape. Moreover, the model should be one that users could navigate and experience spatially. Existing photo-stitching software used in electronic devices such as digital cameras knew how to infer relationships between images from the sequence in which they’d been taken. But Snavely was trying to develop software capable of making such assessments in a totally different way. He devised a two-step process: “In the first step, we identify salient points in all the 2-D images,” he says. “Then we try and figure out which points in different images correspond to the same point in 3-D.”
“The process,” Snavely says, “is called ‘structure from motion.’ Basically, a moving camera can infer 3-D structure. It’s the same idea as when you move your head back and forth and can get a better sense of the 3-D structure of what you’re looking at. Try closing one eye and moving your head from side to side: you see that different points at different distances will move differently. This is the basic idea behind structure from motion.”
Computer vision, as Agüera y Arcas explains, benefits from a simple assurance: all spatial data is quantifiable. “Each point in space has only three degrees of freedom: x, y, and z,” he says.
Attributes shared by certain photos, he adds, help mark them as similar: a distinctively shaped paving stone, say, may appear repeatedly. When the software recognizes resemblances–the stone in this photo also appears in that one–it knows to seek further resemblances. The process of grouping together images on the basis of matching visual elements thus gathers steam until a whole path can be re-created from those paving stones. The more images the system starts with, the more realistic the result, especially if the original pictures were taken from a variety of angles and perspectives.
That’s because the second computational exercise, Snavely says, is to compare images in which shared features are depicted from different angles. “It turns out that the first process aids the second, giving us information about where the cameras must be. We’re able to recover the viewpoint from which each photo was taken, and when the user selects a photo, they are taken to that viewpoint.” By positing a viewpoint for each image–calculating where the camera must have been when the picture was taken–the software can mimic the way binocular vision works, producing a 3-D effect.
As Szeliski knew, however, the human eye is the most fickle of critics. So he and his two colleagues sought to do more than just piece smaller parts into a larger whole; they also worked on transition effects intended to let images meet as seamlessly as possible. The techniques they refined include dissolves, or fades, the characteristic method by which film and video editors blend images.
In a demo that showed the Trevi Fountain in Italy, Photo Tourism achieved a stilted, rudimentary version of what Photosynth would produce: a point cloud assembled from images that represent different perspectives on a single place. More impressive was the software’s ability to chug through banks of images downloaded from Flickr based on descriptive tags–photos that, of course, hadn’t been taken for the purpose of producing a model. The result, Szeliski remembers, was “surprising and fresh” even to his veteran’s eyes.
“What we had was a new way to visualize a photo collection, an interactive slide show,” Szeliski says. “I think Photo Tourism was surprising for different reasons to insiders and outsiders. The insiders were bewildered by the compelling ease of the experience.” The outsiders, he says, could hardly believe it was possible at all.
And yet the Photo Tourism application had an uncertain future. Though it was a technical revelation, developed in Linux and able to run on Windows, it was still very much a prototype, and the road map for developing it further was unclear.
In the spring of 2006, as Snavely was presenting Photo Tourism at an internal Microsoft workshop, Blaise Agüera y Arcas, then a new employee, walked by and took notice. He had arrived recently thanks to the acquisition of his company, Seadragon, which developed a software application he describes as “a 3-D virtual memory manager for images.” Seadragon’s eye-popping appeal lay in its ability to let users load, browse, and manipulate unprecedented quantities of visual information, and its great technical achievement was its ability to do so over a network. (Photosynth’s ability to work with images from Flickr and the like, however, comes from technology that originated with Photo Tourism.)
Agüera y Arcas and Snavely began talking that day. By the summer of 2006, demos were being presented. The resulting hybrid product–part Photo Tourism and part Seadragon–aggregates a large cluster of like images (whether photos or illustrations), weaving them into a 3-D visual model of their real-world subject. It even lends three-dimensionality to areas where the 2-D photos come together. Each individual image is reproduced with perfect fidelity, but in the transitions between them, Photosynth fills in the perceptual gaps that would otherwise prevent a collection of photos from feeling like part of a broader-perspective image. And besides being a visual analogue of a real-life scene, the “synthed” model is fully navigable. As Snavely explains,”The dominant mode of navigation is choosing the next photo to visit, by clicking on controls, and the system automatically moving the viewpoint in 3-D to that new location. A roving eye is a good metaphor for this.” The software re-creates the photographed subject as a place to be appreciated from every documented angle.
Photosynth’s startling technical achievement is like pulling a rabbit from a hat: it produces a lifelike 3-D interface from the 2-D medium of photography. “This is something out of nothing,” says Alexei A. Efros, a Carnegie Mellon professor who specializes in computer vision. The secret, Efros explains, is the quantity of photographs. “As you get more and more visual data, the quantity becomes quality,” he says. “And as you get amazing amounts of data, it starts to tell you things you didn’t know before.” Thanks to improved pattern recognition, indexing, and metadata, machines can infer three-dimensionality. Sooner than we expect, Efros says, “vision will be the primary sensor for machines, just as it is now for humans.”
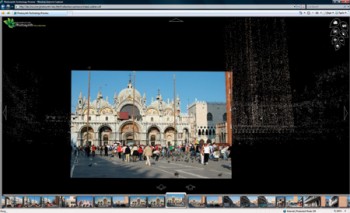
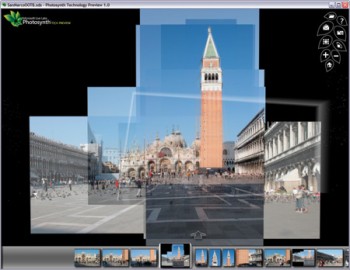
Microsoft is demonstrating Photosynth online with photo collections such as this one of Venice’s St. Mark’s Square. The shots in this collection were taken by a single photographer over 10 days.
Credit: Courtesy of Microsoft Live Labs
What It Might Become
Microsoft’s work on Photosynth exemplifies the company’s strategy for the 100-person-strong Live Labs. Part Web-based skunk works, part recruiting ground for propeller-heads for whom the corporate parent is not a good fit, Live Labs aims in part to “challenge what people think Microsoft is all about,” says Gary Flake, a 40-year-old technical fellow who is the lab’s founder and director. Its more immediate aim is to bring Web technologies to market.
Flake’s pitch about the Live Labs culture is an energetic one, as he speaks about his efforts to bridge research science and product engineering. Flake, who has worked for numerous research organizations, including the NEC Research Institute and Yahoo Research Labs, which he founded and also ran, describes this as an industry-wide challenge. At Live Labs, “we have a deliberate hedge portfolio,” he explains. “We have a very interesting mix,” encompassing “40 different projects.”
Flake is unwilling to discuss many of his projects in detail, but he brims with excitement about his mandate to “to bring in more DNA” in the way of raw talent. “We want to create and advance the state of Internet products and services,” he says, but he also speaks passionately about Live Labs employees as “human Rosetta stones” who can serve as translators in an R&D world where engineers and scientists often, in effect, speak different languages.
The Photosynth project, Flake says, epitomizes the kind of success he wants to champion through his efforts to overcome the traditional divide between science and product engineering. It “represents a serious advancement of the state of the art.”
Currently, Photosynth can be seen only in an online demo, but Agüera y Arcas’s team hopes to release it by the end of the year. What somebody who acquires it can actually do with it remains to be seen. Point clouds can be made from as few as two or three images, so one can imagine users creating relatively unsophisticated synths of their own photography–of, say, a family trip to Mount Rushmore. (Of course, people who have Photosynth might begin to shoot many more pictures of a given place, in the interest of being able to make a rich synth later.) But it could also be that users will tap into online libraries of photos–which will probably have to be downloaded to a local computer–to create their own synths of highly photographed sites.
Still, Photosynth is mostly promise with little proof. Technical questions abound as to how easy it will be to use and what, exactly, its capabilities will be. Also, despite the Linux origins of Photo Tourism, Photosynth will remain Windows only for the foreseeable future.
And for all Photosynth’s immediate appeal, its applications, too, remain unclear. The world doesn’t need another image browser, even a groundbreaking one. It seems even more unlikely that users would pay for Photosynth in its current form. In the meantime, Photosynth’s fortunes will depend on whether it can build a broad-based community of users. Will it take on new uses for those who embrace it, as Google Earth has done? More important, will Microsoft release a final product sufficiently open that such a community can seek uses different from those initially intended?
Flake reports that the Photosynth team has conjured dozens of potential uses, two of which look especially likely.
One is to integrate it more fully with Microsoft Virtual Earth, making it that tool that takes users to the next step in deep zoom. With Virtual Earth handling topography and aerial photography while Photosynth coördinates a wealth of terrestrial photographic material, the two applications could give rise to a kind of lightweight metaverse, to use the term that Agüera y Arcas invoked at TED.
Noting Photosynth’s facility with buildings and city squares, Seitz also envisions a “scaling up in a big way.” “We’d like to capture whole cities,” he says. Indeed, Agüera y Arcas and Stephen Lawler, general manager of Microsoft’s Virtual Earth project, announced in August 2007 in Las Vegas, at the annual hackers’ convention Defcon, that they’re planning a partnership. Once some relatively minor technical hurdles are cleared, Seitz says, “there’s nothing stopping us from modeling cities.”
As people create and store ever greater amounts of digital media, Photosynth might even enable users to “lifecast” their family photo albums. “Imagine if you could watch your kids grow up in your own house,” says Flake, “just from your photo collection.”
As such ideas percolate, the Photosynth team is hardly sitting still. Last summer the researchers released an online demo collaboration with NASA, and now they are working with the Jet Propulsion Lab to synth a small part of the surface of Mars.
One does wonder how far Microsoft is willing to bankroll this kind of geek-out. Then again, as Agüera y Arcas and Flake ask rhetorically, how does one put a value on this kind of technical achievement? For while Photosynth seems somewhat lacking in a clear path to market, it also seems wholly lacking in competition.
Jeffrey MacIntyre is a freelance journalist who writes widely on culture, science, and technology.